【教程】公式化SVC输入源数据处理流程
对于歌声转换,Singing Voice Conversion即SVC,输入源即干声的质量直接决定了输出歌声质量的下限,宛如扒谱无参工程之于SVS。总的来说,我们致力于获得干净和干燥的歌声。
干净,首先指的是这段音频自始至终同时都只有一个人在唱歌,也没有乱七八糟的怪动静。干燥,则是指这段歌声尽量经过尽可能少的后期效果处理,最关键的是延迟和混响。
一般我们有两种方案能够得到质量良好的输入源,各有利弊:
音频分离
优点:几乎完美提取出歌手的转音、咬字等一切特征
缺点:同上。原曲歌手的唱法套用至目标音色未必会有好的效果,比如伍佰《泪桥》中的口音,这时候许多人会选择从翻唱版本开工。
难点:对于和声复杂的歌曲,分离是一种艺术噩梦。
别担心,百花齐放的分离模型还是能一定程度助你脱离苦海的。
自造输入源
难点:说了这么多结果要自己拼
优点:不管是自己唱,还是借助歌声合成引擎,我们基本上取得了对输入源一切的控制权。古尔丹,代价是什么呢?
缺点:掌握自己的音道,或者学会如何在歌声合成引擎中通过几个参数来趋近你希望达到的声音,都不太容易。代价是时间,和钱。
呃...我也不会唱歌,不过你可以瞅瞅上头那个相关阅读。
音频分离
你需要使用一些基于海量高质量音乐分轨训练出来的分离模型,把歌声从一首经过千锤百炼的歌里「拽」出来。
MSST
请查阅这篇文章中的扒谱章节的后半部分
BTW,除了MSST-WebUI,你也可以使用哔哩哔哩@领航员未鸟制作的MSST图形界面,截止到本文攥稿前,它支持新的分离模型(详见此视频)
对于音频分离方案,大抵就是一层一层一层剥开歌的心,分离主人声→分离和声→分别去混响→后处理;或者直接对原曲分别使用提取主要人声、和声的模型。
分离和声的模型确实能够把和声一股脑拽出来,但很多歌都不只有一个和声部。如果你能够清晰判别和声,且仅仅是简单的加减调,那你可以对输入源做整体的增减调,或者对输出音频做变调——这取决于你使用的SVC模型的音区更适合高音还是低音。
还有,如果模型非常固执,就是不把一些歌中的元素当作人声(或恰恰相反),那除了更换各种模型,在这种方法上就没啥办法啦。
RipX Daw
首先,RipX内置的歌声分离算法并不是市面上最顶级的。如果你目标的歌并没有很多复杂的和声,MSST就能取得理想的效果,那就没必要进入这个流程。
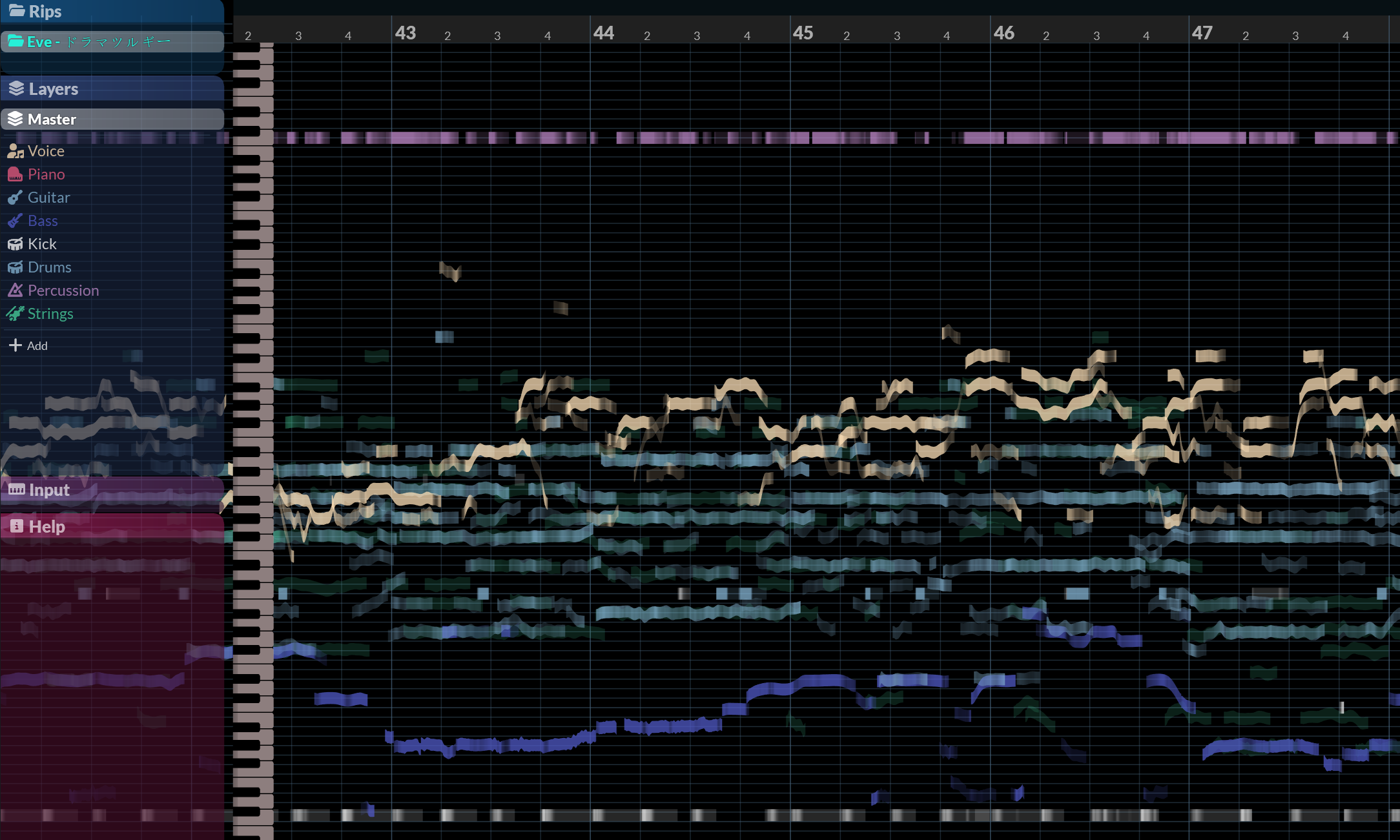
RipX的魅力在于你能够可视化观察与编辑分离出来的每种乐器元素。
涉及到两个人对唱且两句唱词间有重叠的部分,就可以先处理奇数句,删去重叠部分+偶数句唱段后导出,再还原,删去奇数句和重叠部分。
对于和声关系较为清晰的歌曲,也可以直接利用RipX Daw进行分离:一句句来,先确定这个段落有几个声部,再从高到低框选并试听是否正确,然后只保留一个声部(最好是同一个,最基本的架构就是和声一高一低+主旋律人声),重复N次得到不同声部的音频。
因为这段要举例实在有点难,我建议你花半小时看看这个讲的很好的视频。其中对于分离伴奏使用UVR等步骤有些过时,建议从九分钟开始。对这个视频内容的补充说明放在下面。
1.使用经过MSST模型初步分离出的无混响人声,导入RipX,一般只需要勾选Voice作分离。然后,按上上段所述逐句修改。对于主人声中混入的少量和声,这么做也许也能去掉。
2.去混响不建议用RipX,MSST的模型或Waves Clarity Vx - Dereverb效果都显著优于它。
3.18’20开始演示了去除歌声中多轨录音得到的重叠音的方法。针对句尾长音,建议拉长时不要用RipX,导出换Melodyne、Vovious等专业修音软件,或者Reaper,它们有更加自然的时间变调拉伸算法。
4.22‘50开始展示了对原曲转音适当平滑以获得更自然的转换后歌声。我的建议是,如果这一部分的分离干声没有叠加和声等其他问题,也使用更好的修音软件来干这个活,RePitch、Vovious、VocalShifterLE(这个免费)都支持识别和修改原曲的Pit线。后面演示的方法不太普适,建议发动鬼脑。
5.后期修复不在本文讨论范畴之内;另外,后期主要是修音高,用混响等遮遮丑,吐字咬字错误拿原曲或其他歌手的音素去拼的话,这个得放在邪道里头。
自造输入源
哈哈终于到我的舒适区了。
歌声合成
出门右转这篇文章......
多说几句。
为了确保你拥有最佳的效果,建议使用上文中提到的音频转MIDI且提取音高包络线的玩法。即使你不购买SynthV、ACE Studio等商用歌声合成引擎,也有免费的Diffsinger+SOME玩。
在选择作为输入源的歌姬时,尽量遵循:目标歌曲的语言和歌姬数据集语言相同,歌姬没有很有特色的口音,如果你的SVC模型是男声,输入源最好也是,反之亦然,无生物音源出去。
扒谱相当于对歌曲声部的还原,工作量无论如何都要比MSST直接分离大。如果你面临两难的境地,那就看是利用RipX等类似工具对干声庖丁解牛,还是一鼓作气把和声扒出来。选择中遵循的原则,除了效果至上还有一点,慢扒out。
自己唱
就像很多做SVC换声的UP主也会倾向于直接从歌曲的翻唱版本入手,理由有很多:加的效果器更容易分离干净、吐字咬字更清晰合适、音域更贴近自己要用的SVC模型......
(⊙﹏⊙)这里没有录音教程,因为在绝大多数情况,你除了按上一段说的这么做,也可以按上一个小标题那么做,自己唱对于出效果在各种意义上是一个不推荐的选项。
邪道
如果你的电脑里有Melodyne、RePitch、Vovious(才发布没多久)等修音工具,他们在音高识别上比RipX Daw做得更好。因此,利用他们来判别和声关系,或者分离段落和声也会是个不错的选择。
如果你觉得丢什么干声进去,转换的效果都不咋地,肯定是你的模型太逊了!运用控制变量法,相同数据用DDSP(的好几个版本)、RVC、SoVITS都试试,找个效果最理想的。
如果你觉得转换后的呼吸声、吐气声很不自然带电,那你是对的。把原曲的呼吸声剪出来替换,或者挂个DeBreath类VST把呼吸声全干掉,这取决于你。
如果你还想和传统派玩一玩,不妨看看这个并非野路子人力教程。当你遇到SVC模型转换出来的发音有问题时,比如某个音素的起音发音不准,可以将裁剪出来的原音音素拉齐音高拼贴在恰当位置。
如果你既想拥有SVS那样的歌声调校自由度,又想换成自己喜欢角色的声音,那你可以利用搜索引擎搜索:UTAU声库制作教程、Diffsinger声库自训练教程、ACE Studio自训练(这个订阅制且贵且在线合成),然后一头扎进自训练声库的深渊。
合起来
组合使用上述工具达到最高效率!

我们总是希望音频经过的处理步骤尽可能少,降低每一步处理引入的音质损失;另外,我们总是希望尽可能优先使用产出音频质量最高的工具,能用MSST就不用RipX Daw,能从原曲分离出不错的效果就不折腾虚拟歌姬或者自己唱。
如果主人声分离比较顺利,但和声太麻烦,我的建议是摆烂。或者,和声部分得自己努力扒谱出来,简单的直接从主人声整体变调得到,复杂的在歌声合成引擎里写出来,丢给某个歌姬导出音频,再丢给SVC模型。