【教程】如何公公又式式的制作一首虚拟歌姬翻调
记录一下这一季度我的虚拟歌手翻调稿件大概是以什么流程制作的。
在这篇教程中,我们通过从零开始制作松下優也 - Mr. "Broken Heart"的虚拟歌姬翻调稿件,希望有助于刚接触虚拟歌姬调校的爱好者初步建立易上手的工作流,或让感兴趣的人对一首翻调如何诞生有大致的了解。
素材准备
为了制作一个翻调,我们需要获得:原曲人声扒谱的工程文件、去除人声的伴奏。工程文件好比人类学习演唱时会借助简谱、五线谱,是指导虚拟歌姬正确演唱的基本必要素材。伴奏在我们完成调校,进入混音流程时有用,也可以在调校阶段以较低响度混合,把握合适的声线取向。
这一阶段的准备方案具备优先级:本家配布>他人分享≥自己提取制作。
扒谱
一些歌曲为了便于二创,会提供官方人声MIDI,多见于同人音乐和术力口歌曲。此外,如果这首歌存在官方流出的扒带,其中也可能包含人声MIDI。
如果不提供,我们可以退而求其次,尽量不重复造轮子,去借用他人扒谱的工程。可以是Bowroll,vsqx分享平台,或一些扒谱者自己建立的工程配布站;同样,我们可以在更加广泛的分享歌曲MIDI扒谱的网站,如Midishow,Online Sequencer;实在不行,如果你能够获得这首歌人声的五线谱PDF,可以尝试ACE Studio提供的在线PDF转Music XML工具......
记得对他人的工作成果常怀敬畏与感激之心,认真阅读Readme.md等对方的使用授权申明,至少在最终成品的简介附上扒谱者的署名。
无论你获得的是UTAU的.ust,VOCALOID的.vsqx/.vpr/.vsq,OpenUTAU的.ustx,SynthesizerV的.s5p/.svp等各种虚拟歌姬软件的工程格式,都可以轻松地通过使用Utaformatix(在线)或libresvip(本地)双向转换,后者能够处理ACE Studio的.acep,我个人更常用。
如果我们万策尽,不得不自己扒谱呢?
1.对于编排不那么复杂的一些流行歌曲,我们可以试着扒谱,因为你可以更加依赖听感,而暂时忽略乐理音阶的助力。通过反复听——确定音高和时长——听下一个音符的循环,最终就可以完成扒谱了。
2.这需要经验、需要耐心,社群中不乏接取无偿/有偿扒谱的创作者,与人合作是不错的选择。
3.也可以借助一些辅助工具,这是我近期最常用的模式。假如你是ACE Studio或SynthesizerV Studio的用户,它们都内置了人声转MIDI的功能。不是也没关系,由OpenVPI开发开源的SOME:Singing-Oriented MIDI Extractor功能差不多,三者效果难分伯仲。
在兴致勃勃地把音频丢进去转换前,为了尽可能提高转换后扒谱的准确性,我们仍有一些活可干。交给模型的输入人声越干净,输出扒谱就越准确。我建议遵循以下步骤:
1.获得无损、电平良好、和声分离的人声干声。这部分几乎很难找到官方分享,我们需要借助基于海量分离音轨训练的神经网络模型。在线的可以选择mvsep,团子AI等;本地的现阶段用MSST即可,我使用MSST WebUI。

就本地MSST模型选择展开一说,我主要使用两个模型:mel_band_roformer_vocals_becruily 和 bs_roformer_karaoke_frazer_becruily。首先将原曲的无损音频丢进去,尽量在输出选项选择wav 32bit,可以避免提取后的干声丢失0dB以上的信号。前者模型会将伴奏和所有人声剥离,因此我们得到主人声和伴唱和声在Vocal文件中;接着,使用karaoke模型将主人声分离至Vocal,伴唱和声分离至inst。
2.去混响:分离的音频中通常伴随着混响,这会干扰音高提取模型的判断,因此,我们同样可以继续使用MSST,找一个合适的Dereverb去混响模型,得到比较干净的声音。此外,Waves Clarity Vx等音频插件厂商推出的同类插件亦可。
如果一些地方出现了提取不干净的杂声,可以在Adobe Audition等任意音频编辑软件中静音无关部分,或者使用一个门限器(Gate)来滤除低于一定响度的声音。
导出音频为单声道即可。不过,有些歌的和声左右声道实际上是两个声部——参考我翻调的这首Be Brand New。
因此,我们需要将分离和声的左右声道分别保存为独立的单声道音频,扒谱为两个轨道。他们在唱法细节上有所不同。
3.确定歌曲的BPM(Beat per Minute)。
在网易云的歌曲百科页面可以直接找到:
如果这首歌没有上架网易云,可以使用团子AI开发的节拍分析工具,免费本地计算;SynthesizerV Studio 2亦内置音频节拍检测工具。
4.人工校对清理:转换结束,但还没完。
SynthesizerV Studio 1的音频转MIDI功能相对最齐全,内置了ASR和音高线提取。由于几乎不存在音素识别完全准确的情况,人工逐句校对是必须的。针对音高与节奏,如果音频分离的质量足够理想,通常不会有什么问题。如果发生错音和吞字,则需要自己定位并修正。对于没有内置音频音素识别功能的SOME,只能自己灌词了。
灌词食用小技巧
我不会日文片假名,因此在灌词时必须参考罗马音。但非热门歌很可能没有人制作罗马音歌词,不妨借助AI。
在灌词时,同时参考原曲、提取后人声、AI从片假名转换的罗马音,以及扒谱模型的识别结果,爆破音辅音是较容易混淆的对象,需要小心辨别。
对于歌词,我们将音素对齐放到调校环节,此处只考虑提取音素是否正确表现了发音。对分离出的和声执行同样的步骤,我们最终可以得到适合调校的工程。
BTW,如果一首歌中的和声只有一个声部,且听得出都是简单的升降几个key,我们也可以自行从主轨复制相应部分。但由于扒谱模型精度而产生的适度时值偏移有时也会让整体的人声表现更加真实自然,没有特别想法的话,不妨按原曲的处理方式来。
和声分离并不是万能的。对于作为示例的Mr.Broken Heart这首歌,歌曲后半部分的和声就包含两到三个声部,这种情况就需要自己动手了。
5.加一点细节?
我指的是呼吸声,这些音频转MIDI模型不会识别出歌手的换气声,如果有需要,可以自己添加br音符之类;或者,“借用”一下本家的呼吸声,也行吧...
伴奏
一般来说,对于虚拟歌姬主导的术力口歌曲,有名气的P主通常会在piapro或Google Drive配布官方伴奏,部分还提供±3key的版本。这一部分结合上方我们获得人声干声的方法,对找不到官方伴奏的情况作补充。
影响提取伴奏质量的无非输入端音质和模型质量。后者需要等待技术进步,前者最好获得原曲的无损音频,请参考这个视频,不赘述。
当获得纯净干声的时候,纯净伴奏作为副产物也自然而然取得了。通过更换MSST的模型,比如mel_band_roformer_karaoke_becruily.ckpt就会将主人声和伴奏+伴唱和声分离,直接得到和声伴奏。
调校
尽管这部分按顺序排在素材准备之后,但调校也可以和扒谱并行工作,即完成一段乐句的扒谱清理校对后即刻进行更加细节的调校。这里只是为了行文方便。
事先声明:这篇教程侧重于描述虚拟歌姬翻调作品的整体产出流程,而非聚焦于调校这个核心环节。如果需要深入学习调校,烦另请高明。
1.歌手&声线选择:让大叔唱小甜歌,少女演绎男低音,也许很酷——你清楚地有意为之的话。为了便于调校,我们还是倾向于选择声线与原曲风格相近的声库。此外,如果演唱者的音域对选择的声库稍显困难,整体升降调也是可考虑的,别忘了对伴奏也这么做。
此处,我们选择Dreamtonics官方发布的原生英文声库Liam作为演示,并适当全局拉高 Bright 声线以贴近原唱。
在真人的演唱中,声线往往是动态变化的。我们可以将歌曲分为主歌、副歌、过渡段等几个部分,聆听并总结歌手在每一部分的演唱特质(音色、咬字、气息...)。借助声线自动化,可以在段落间营造变化,降低重复的无趣感。
对于没有提供声线参数的调声引擎,我们也可以通过调节段落的整体性别、张力、气声达到类似的效果,或者在后期混音时针对不同段落作差异化的音色塑造。
2.音高流转:Pit无疑是调校入门最先开刀的参数。拉音头音尾,画颤音转音......各种引擎十几年积淀下的教程中,Pit的调校方法基本是可以在引擎间迁移共通的,这里就不作展开。
3.音素,快慢与强弱:歌唱时,每个音素的发音是不均匀分配的。比如,如果辅音较长,这个字的发音就呈现得慵懒而拖沓。微调音素时长的目的是增强吐字衔接的流畅性,减少棒读感。强弱变化亦然,咬牙切齿地唱着恋爱循环,那种事不要啊。
4.张力、气声、发声与响度:虚拟歌姬发出自然清晰的气声很不容易,比如SynthV的气噪问题久为诟病,也迟迟难以解决。以至于一些调校者会在后期混音时下功夫,通过自动化重新塑造出满意的高频气声。总之,这几个参数联动可以控制歌姬歌唱的虚实。
说了这么多还要自己调,到底谁是歌姬(恼
针对每个调校引擎独有的参数,难以详述。例如在使用SynthesizerV Studio 2时,多加利用新增的口型参数可以使发音更加自然,实现原本需要多个参数联动的效果。
混音母带
哦耶,恭喜你已经完成了最麻烦的部分。不过接下来的环节也挺麻烦的。
具体的混音教程同样不是这里的重点,对于基本的处理,可以参考如下视频:
对于这首歌,我大致混完就是这样:
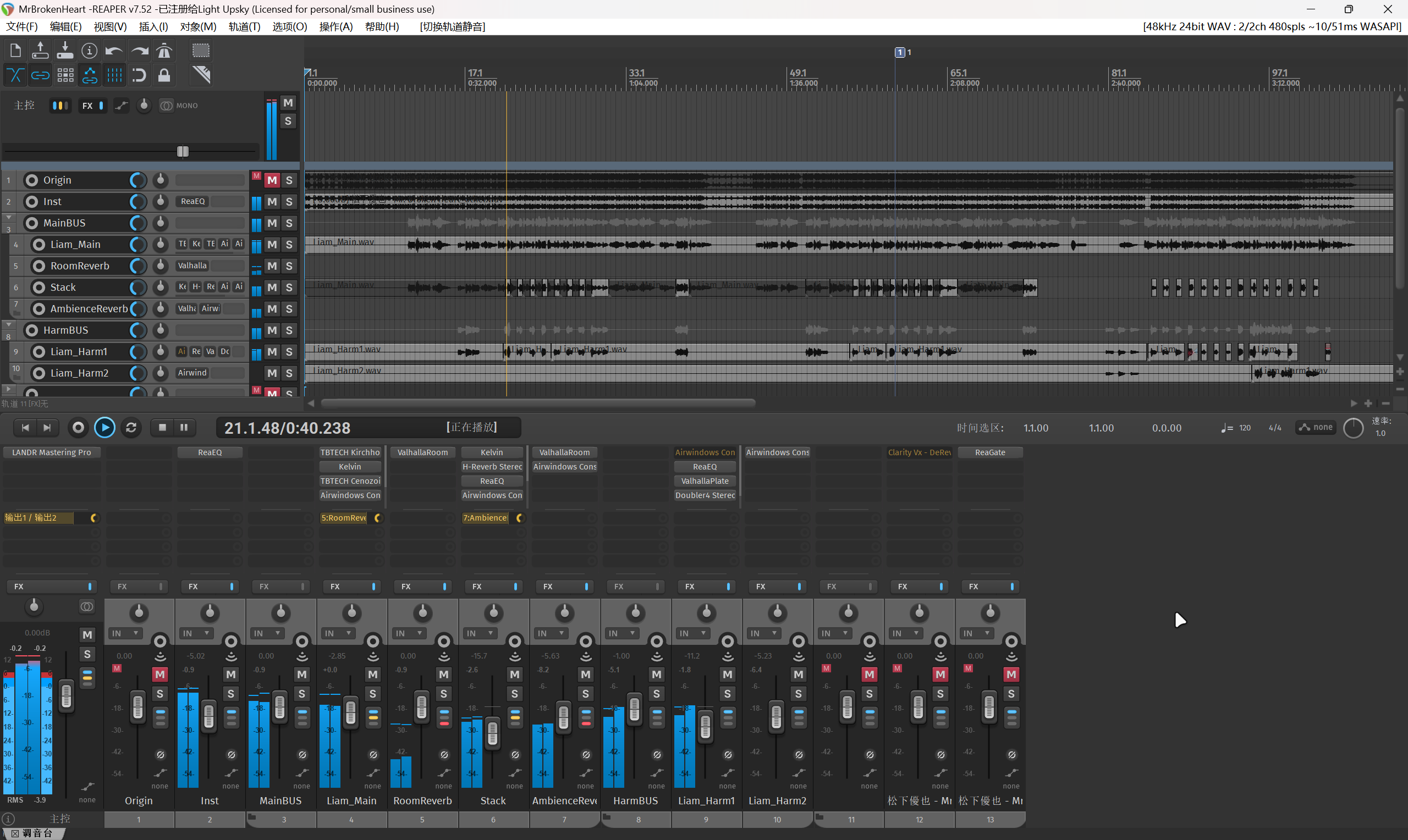
我认为,在对人声干声的处理之外,比较关键的是掌握一些歌曲中特殊效果的制作技巧。比如这首歌在副歌几乎每句句末几个词上除了升调的和声,还叠加了一层原调的和声来增强空间的包裹感。这里我选择手动复制一轨主唱并剪裁出这些部分,当然,也可以借助绘制包络线来实现。还有一些常见的人声效果,可以参考虎皮猫老师的视频:人声混音特效怎么做?
对于母带,我们可以暂且简化理解为对整体音量做标准化,以及风格化。在进入母带流程之前,确保你的每一个音轨在播放全程没有爆红,即不超过0dB,且总轨也是如此。你可能需要将每个轨道的推子都向下拉,在不爆音的情况下保证各自的响度平衡。
针对响度,需要参考各流媒体平台的媒体响度标准。由于国内流媒体平台似乎均未公开后台响度控制标准,我们只能以这篇文章为参考,即-12LUFS。贴近标准响度的意义在于尽可能避免上传的音频被平台自动化算法二次压制,导致音质损失,不过,本来平台的音频压缩码率就很感人啦...
面向视频平台输出
既然是“公式化”,为一首翻调约稿、制作精美动态PV均不是这里推崇的操作。除非你是超强力绘画剪辑特效一体机......抱大腿.jpg
通常我会遵循以下路径:
1.是我喜欢的MV,直接使用。如果原曲有MV,或者他人制作的音频可视化、歌词展示,那就得用。和上文中使用他人的工程文件一样,尊重创作是每个人的义务。你可以通过站内私信,简介引用等方式向原始创作者表达敬意,如果对方确实不希望你使用,无妨,天无绝人之路。
2.音频可视化+编辑器界面录屏(调声晒?)。从AdobeEffects到剪映,移动端的AlightMotion等,都具备制作音频可视化+歌词PV的能力。关于使用剪映内置字幕识别+歌词模板的效果,可以参考我的这个视频:
3.这个项目:UST-Visualizer能够将调声工程的音符与音高可视化为序列帧,比录屏可玩性高一些。
无论选择什么模式,我都建议使用MKVToolNix在上传前将音频与剪辑好的视频再次混流,确保视频内含的是无损音频。以bilibili为例,至少24bit 48kHz的音频能够开启无损Hi-res(大会员专属)模式。
结语
作为示例的翻调过几天上传。