虚拟歌姬比真人歌手更强了吗?别太担心。

注:本文攥写时间跨度超一个季度,可能存在信息过期等潜在问题。
2025 年 2 月 13 号,Dreamtonics 发布了旗下歌声合成引擎 Synthesizer V Studio 的大版本更新预告:Synthesizer V Studio Pro 2(以下简称 SV R3)。
![]()
而在虚拟歌姬社群内,对这一『重大更新』态度却褒贬不一。社区的疑虑主要有以下几点:
- 1.可调性是否下降了?智能音高曲线作为 R3 的卖点功能看着不错,但如果告诉你这无法关闭,对于调校师就并不友好。口型参数也许是调校中可感知的升级点,但效果缺乏样例。
- 2.音质提升了多少?自 R2 中后期版本,气噪就成为了 SV 不可忽视的重要问题;就目前 R3 声库的演示视频来看,似乎并没有非常有效地解决。其次,R2 的音质在本地离线的歌声合成引擎中已经非常不错,R3 的进步远没有从拼接到 AI 技术那样震撼。
- 3.工作流并没有革新性的变化——抽参、随机采样应该是理想的调校“大众化”方案吗?
- 4.激活码升级至账户系统的抢位问题、第三方声库高昂的升级价格…
我从听众转变为调声爱好者三年多,先后使用过 UTAU、VOCALOID、Synthesizer V、ACE Studio,即便是作为爱好,在支持正版软件上也投入了 3k+元。
在接下来的讨论前,先说结论:无论你是歌手、调校、音乐人还是听众,当前虚拟歌姬仍然谈不上取代真人歌手,辅助音乐人创作的工作流仍有待完善,也无以引发劣币驱逐良币的问题——目前,这主要是 Suno 和泛滥的 SVC 工具导致的。
以免这三者引发混淆,我们先作个简单的概念界定。
歌声合成、歌声转换与音乐生成
传统的歌声合成采用拼接形式,声库内包含一定标准要求的(例如 CVVC),分音阶的音素采样,以 UTAU 为例,依据输入的音高和发音标记借由 world、moresampler 等合成器拼接成预期的读音。
合成 vs 转换
歌声合成并不是非常历史悠久的技术,以雅马哈旗下的 VOCALOID 作为起点,2003 年至今也不过二十年出头。而这里的歌声合成均指的是 SVS,下面我们用一张 Deepseek 生成的表格简单对比歌声合成与歌声转换。
| SVC(歌声转换) | SVS(歌声合成) | |
|---|---|---|
| 输入 | 原唱录音 + 目标音色样本 | 乐谱、歌词 + 音色参数 |
| 输出 | 原音频换音色 | 全新生成的歌声 |
| 场景 | 翻唱、音色替换 | 虚拟偶像、原创歌曲 |
| 上手难度 | 低 | 相对高 |
| 训练成本 | 相对低 | 相对高 |
AI 奶龙、AI 孙燕姿等你先前在互联网大量刷到的 AI 翻唱,可以说 90%+使用的是歌声转换技术,这方面由于有开源的 RVC、DDSP,只需要收集 10~30 分钟的目标音色的音频数据就可以训练其音色模型。
音乐生成
Suno 生成的音乐初听确实很惊艳,尤其是与之前的音乐生成方案对比之下。给出一段填词(甚至可以让 LLM 代劳),选择特定风格,数十秒间像模像样的音乐就诞生了。
但它真像模像样吗?作为一种低成本的娱乐化方案是人之常情,那如果你是在网易云这样的流媒体平台被推荐到了一首 AI 音乐呢?很容易就能听出端倪:糟糕的混音,吊诡的人声音质和发音,不那么一致的乐器音色…
直到 Suno4.5,这里的评论仍然有效,尽管进步是肯定的。我们会在下文再度提及与拓展这里的内容。
至少直到今天,AI 生成音乐还不能和一个学习过基本乐理的独立音乐人相提并论。
怎么才算好的歌声
虚拟歌姬最初并不是一个独立的音乐流派,VOCALOID 推出时的目标/野心就是成为媲美真实歌手的虚拟音源,就像你今天在 DAW 内使用的乐器软音源那样。不过我们也都知道,时至今日,实录乐器依然是高质量歌曲创作的首选。
btw,ACE Studio 近期(5 月中旬)推出了 AI 小提琴功能,可以通过仅输入 MIDI 输出包含动态力度、技法的小提琴音频,且不提其也想成为 DAW 的野心能否实现,AI 乐器也许会是未来数字音频厂商新的竞争点。
在当时虚拟歌手没有掀起什么风浪,术力口围绕自己的 IP 而催生了一套独特的创作生态,原创曲、MMD、弹幕文化,在开放包容的氛围中和谐发展。
也许有些人沉醉于画面与声音的结合,有些人痴迷于欣赏音乐和歌唱的奇观,更或者只是单纯地发个弹幕参与娱乐——围绕 V 家形成的「你中有我,我中有你」的生态,证明了当时运营方式的正确和有效,也让创作得以收获成果。
——虚拟音声浮沉二十载(上):往昔溯源
今天,合成歌声成为了“超越人类水平”的歌声了吗?在 Dreamtonics 创始人华侃如所作的 ADC23 主题演讲中提到了通过主观质量偏差测试衡量合成声音自然度,即让志愿者对打乱顺序的真实和合成音频样本评分,以获得代表感知质量的数字,进而评估歌声质量,似乎确然得出了合成歌声>人类演唱的测评结果。
在早些时候,Synthesizer V Studio 1 就尝试引入 RLHF(人类反馈强化学习)来提高自动音高生成的表现力。
然而,在应用了上述调研结果的 SV R3 中,效果好像远远达不到这样的宣传标准。
什么出了问题?
你做的是工具
是这样的。 我当时真的很想自己唱歌试试看,于是写完自己试着录了歌,拿去给朋友们听。大家听完都说不错,但是也直接或委婉地表达了,你要不要再用用洛天依啊。
我就没办法了,掏出V开始调,调完一些放进去第一次听的时候愣在那。
是我在唱歌。
我知道我们的嗓音天差地别,但是我一瞬间就认得出那个熟悉的女声就是我在唱歌。我又给朋友们听,不是错觉,他们也感受得到。我现在给你们听,你们也感受的到。
虚拟歌姬本来是没有灵魂的,而我们相处太久了,互相浸润太久了,我把灵魂分给她们一半,她们把歌声分给我一半。 我不是悲伤,我也不知道怎么形容。所以我把这个歌给你听,我把这个故事也讲给你。故事叫 《世界对面的另一个我,但她是纸片人》
——ilem《白鸟过河滩》置顶评论
从来无须否认,虚拟歌姬与 P 主已经是超越工具和人的关系。我们有这么多以歌姬人设、世界观为基创作的作品,赋予其强大不息的生命力。因此,这个部分绝不是呼吁谁成为歌姬工具论的簇拥。
不过,作为歌声合成引擎,一款面向消费者的产品,事情就很明了了,你做的是工具。
不管你面对的是“专业音乐人”,还是什么都不懂的小白,还是 PVP 大佬,任何一项改动都必须对消费者负责。
作为一款工具,SV R3 就没那么称职了。
“智能”音高曲线在普遍情况下减少了一定的工作此言不假,但牺牲了百分百的可调性,尤其是在语调校这样需要对 Pitch 进行完全调整的情况下,和用户抢鼠标绝对是不愉快的,更不要提在发售的第一个月这项功能错误百出,几乎完全让用户丧失自行调整、给 AI 修改错误的可能。
从我个人的体验,声线参数变得超级敏感与不稳定,张力参数亦然,甚至不如 SV R2 的表现。以 ROSE V2 为例,稍微动一下张力参数,即引入这一处理环节,就会极大的改变其音色,这种变化是非线性的,导致我很难把握调整的力度。
需要补充的是,ACE Studio 以外的大部分 AI 歌声合成引擎的参数实质上都是音频效果器的组合。简单来说,引擎先合成歌声音频,再经过一道道参数的处理,最终获得我们听到的音频;而 ACE 走云端方案,张力等为实参,即在声库合成阶段就引入的参数,效果更加自然,但也增加了性能开销,开放本地离线合成的希望就很渺茫。
跨语种功能也获得了史诗级削弱。如果说 R2 的跨语种是微妙带有音源原语种咬字特性,但基本符合相应语种发音规范的效果,R3 的跨语种就完全是幽默。究竟是技术上的限制,还是商业策略,导致 R3 跨语种采用了仅使用音素拟合的方式,而导致发音极不标准,平翘舌音不分,衔接更不自然,我暂且蒙在鼓里。
至于一些专业音乐人非常需要的 VSTi 与 ARA 功能,R3 确有改进,但截至 2.10b2 仍然未能修复各种 DAW 中形形色色的问题,不过相比前面几点还好了。
多样化
现阶段,歌声合成能吸引到专业音乐人比较主流的一点是用于制作试唱 demo,调整编曲和为真人演唱提供参考。鉴于请到合适的真人歌声帮助存在金钱上、时间安排上的客观困难,这倒确实是个好的理由。
目前 Synthesizer V 共有大约七十款歌声数据库,但它们真涵盖了所有艺术家需要的音色了吗?
Dreamtonics 解决音色多样性的方案是:推出 Vocoflex 插件,一款能够随意转换歌声银色的软件。他带来了两个问题:
-
- 号称“安全与公平始终为先”,使用 Vocoflex 需要 KYC 验证,即向第三方提供身份证和面部照片,以将软件与生成内容水印与自然人绑定。用户如何相信自己的隐私不被泄露,在外国音频论坛不难见到大量质疑;在 RVC 等开源软件自由使用的前提下,仅凭Zero Shot+CPU 低延迟处理 卖 1399,性价比低了点吧。
-
- 音质:一言以蔽之,不会比开源软件的音质更好。
再举另一个例子,ACE Studio 提供一百多种声库选择,同时引入了声线混合功能,允许将两个或多个声库的音色与唱法按比例混合成新的声线。这是个不错的方向,尤其是在无需具名或申请商用授权的声库上。
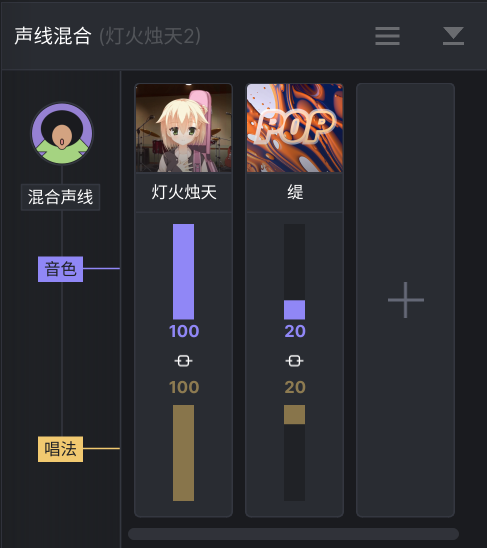
BTW,SV 引入说唱模式来便利 Rap Vocal/语调校的编辑难度,ACE 提供合唱模式快捷生成多声部多相位的歌声轨,也都是积极的尝试。
不过想要更多音色,还是得爆米… 比如你想要一个摇滚音色,几乎很难通过后期效果完全实现(比如 VOICEDRIVE VST),就得买个HOVOC 这样基于摇滚歌声训练的声库,-599 元(好像不止)。
取代调校,可行吗?
让我们先摘几个 Dreamtonics 官网 Synthesizer V Studio 2 介绍页面的用户评价。
“Synthsizer V Studio 2 Pro 的唱法控制非常细腻,音色丰富多变,AI 重录功能时常带给我惊喜。它媲美真人歌手的表现力,完美适配游戏等多元场景的配乐需求。”
小旭音乐 CEO,AIGC 艺术家,游戏音乐知名品牌,资深音乐制作人
“Synthesizer V Studio 2 Pro 创新性的改变了软件的操作逻辑与用户习惯,我现在使用它会更加高效与便捷,我开始放弃使用 Automation 的线条去慢慢雕琢,把修改的繁琐交给这个更加精准控制的算法,现在我可以舒服的躲在屏幕后面发挥自己的 Vocal Production 的审美优势,让人声合成这个技术回归它应有的样子。”
电子音乐制作人 / 唱作人 / 混音师,曾获金曲奖最佳录音、金鸡奖最佳音乐、伦敦国际设计奖等殊荣
“Synthesizer V Studio 2 Pro 是歌声合成技术的再次进化,优秀的软件能让艺术家专注于创作,不需再花大量时间研究如何做出逼真的人声,只需要输入音符与歌词,Synthesizer V Studio 2 Pro 将自动为你呈现最佳效果,从而让艺术家更多的专注于对音乐作品本身的打磨。”
Midifan 电脑音乐在线社区创始人、Buchla 模块合成器演奏家、视觉艺术家、「交流方式」合成器线下活动组织者
你也可以在 D社官网亲自查看这些评价。
这展现了一个趋势,即从 SV R2 1.9 版本或稍早开始,D社有意向“取代调校”的方向技术转型,尽管在 R2 自动音高并没有取得非常好的认同。
有趣的是,一边面向优秀创作者——大部分有调校基础的用户收集意见,一边悄悄放弃他们,继续制作"stable"的自动音高取代手动功能,把这部分用户优化掉——联想到某些游戏“恶意氪金”的笑料,令人忍俊不禁。
给你一分钟时间,你能想出一个主流音乐人在自己的发行作品中使用虚拟歌手的吗?在大众尚不能分清侵权频发的 SVC 与商业化 SVS 的差异时,这种专业化进军或者说低门槛化、普及化是否未免操之过急了。
不会长久…
即便是离线合成产品,也离不开运营维护。
离线可使用≠完全离线使用。
在 SV R3 中,每隔约 10 秒会向服务器发送请求,轮询确保账户在线状态,否则应用会被立即锁定直到网络恢复。在 R2 中,激活需要向服务器发送验证,你可以同时在三台设备上使用同一个激活码激活和离线使用 R2 编辑器。
歌声合成不过二十几年的历史。如果服务器关闭了,这些所谓永久授权的产品还能使用吗?
这种担忧并非空穴来风。Synthesizer V Editor,即 SV R1的激活服务器就曾经在 R2 发售后的一段时间内停止了,从而强迫用户升级到 R2。目前他们又开着了,但这项服务并没有担保。
此外,涉及到更新维护,非常显然,在 SV R3 发售后,R2 停止了购买渠道,并且至今、直到可预见的未来,都不会再有维护更新。这句话并不确定,Dreamtonics 显然面对 R3 的大量问题修复和亟待改进忙得焦头烂额,鉴于部分 R3 声库还同时发售了 R2 版本,也许 R2 不会像 R1 那样完全停更。
D 社官网十分风趣地介绍自己的公司:“Being a small team, we tackle problems that large corporates can’t efficiently solve.”
嗯… 官网的迭代速度确实比产品快,就是什么时候能把官网的中文 i18n 补全,并且改掉汉字显示效果不佳的 NotoSansCJK JP 呢?未知sleepwalking 是否记得年少时在贴吧正义的爱国情怀发言了。
像 ACE、XS Studio 这样的云端产品,没准哪天就消失了。ACE 的国际特供连续订阅两年自动升级为终身会员已经引起了区别对待的不满,和对可持续性的隐忧。XS 背靠网易云,但除了活着毫无动静。
至于本地合成软件,说句难听的,这些软件的可获得性最终是破解版来保证的。
对厂商的朴素信任一旦崩溃,他们能否找到新的用户基本盘来维持运营和研发投入?

跟我的 0.1 折券说去吧.jpg
后记
突兀结尾如何呢,间隔有点久而且迎考比较忙碌,原本这篇文章就难产废了,不过还是基本补完了。
可能看起来有点跑题,因为 SV 的恩情还不完。